线性神经网络
本文最后更新于 2023年12月23日 下午
深度学习——线性神经网络
线性回归的输出通常是预测目标的值,softmax回归的输出通常是预测目标的概率分布
1. 线性回归
问题类型
线性回归通常用于预测一个连续的目标变量,比如房价与房龄、面积的关系:
\[ \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b. \] 更为一般的会写成: \[ \hat{y} = w_1 x_1 + ... + w_d x_d + b = \mathbf{w}^\top \mathbf{x} + b. \]
输出层
线性回归的的输出就是模型的原始预测值,比如输出的是5000就代表\(\mathrm{price}\)是5000,一般不会再经过任何变换。
损失函数
线性回归的损失函数通常使用均方误差损失函数(Mean Squared Error,MSE)当样本\(i\)的预测值为\(\hat{y}^{(i)}\),其相应的真实标签为\(y^{(i)}\)时,平方误差可以定义为以下公式: \[ l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2. \] 为了度量模型在整个数据集上的质量,我们需计算在训练集\(n\)个样本上的损失均值 \[ L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. \]
2. \(\mathrm{softmax}\)回归
问题类型
用于多类别分类问题,其中每个样本属于且仅属于一个类别。\(\mathrm{softmax}\) 回归通常用于处理分类问题,例如图像分类,手写数字识别等。
输出层
输出通常是模型对每个类别的预测概率分布。\(\mathrm{softmax}\)回归的目标是将输入样本分类到多个类别中的一个,输出是一个概率分布,表示每个类别的概率。
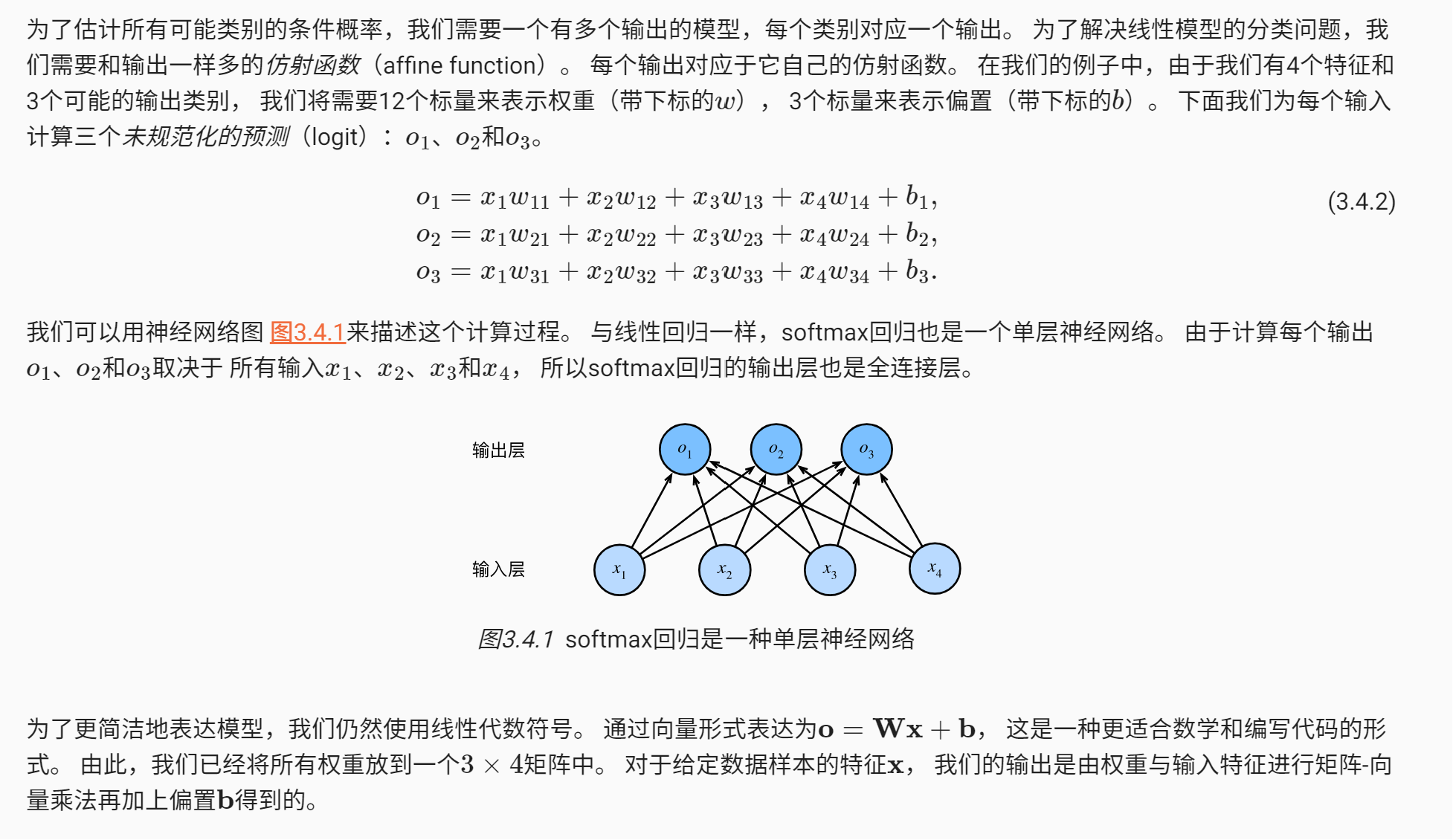
\[ \begin{aligned} \mathbf{O} &= \mathbf{X} \mathbf{W} + \mathbf{b}, \\ \hat{\mathbf{Y}} & = \mathrm{softmax}(\mathbf{O}). \end{aligned} \]
其中\(\mathbf{O}\)是未规范化预测,\(\hat{\mathbf{Y}}\)是预测的概率分布,输出层单元数与类别总数相同。
损失函数
通常使用交叉熵损失函数(Cross-Entropy Loss),这里推荐一篇博客【一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉】,熵意味着不确定性,在物理学中熵越大,说明系统的混乱程度越大,而在这里交叉熵可以理解为实际的系统(概率分布)与预测的系统(预测的概率分布)之间的差距,因此适用于多类别分类问题。交叉熵损失通过比较模型输出的概率分布与实际标签的概率分布来衡量模型性能。 \[ l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. \] \(y_j\)这里是实际的概率分布,在单分类问题中可以看成是某一类别的独热编码,而\(\hat{y}_j\)是预测的概率分布,交叉熵是用来衡量两个概率分布之间的相似性或差异性的一种度量,交叉熵越大说明实际的概率分布和预测的概率分布的越大,通过梯度下降可以降低交叉熵损失函数值。
举个例子,比如有一个猫、狗、人的单分类的图片分类器模型,标签对应的独热编码为:
猫 狗 人 \([1,0,0]\) \([0,1,0]\) \([0,0,1]\) 由于是单分类问题,一张图片中只会有猫、狗、人中的某一种,不会出现猫和狗同时出现的情况,因此类别对应的独热编码就可以视为是实际的概率分布,比如有一张图片的标签为\([1,0,0]\),则可以确定这张图片实际为猫的概率为1,为狗、人的概率均为0。
同样是这张图片,经过模型\(\mathrm{softmax}\)之后预测的概率为\(\hat{y}_i=[0.5,0.4,0.1]\),即预测为猫、狗、人的概率分别为0.5、0.4、0.1,现在用交叉熵损失函数计算预测与实际的误差: \[ l= -1 \times \log 0.5-0 \times \log 0.4 - 0 \times \log 0.1 = 0.301 \] 再考虑两个极端情况
预测的概率为\(\hat{y}_i=[1,0,0]\),即完全预测正确
交叉熵为: \[ l= -1 \times \log 1-0 \times \log 0 - 0 \times \log 0 = 0 \]
预测的概率为\(\hat{y}_i=[0,0.5,0.5]\),即完全预测错误
交叉熵为: \[ l= -1 \times \log 0-0 \times \log 0.5 - 0 \times \log 0.5 = +\infty \]
可见在完全预测正确的情况下交叉熵最小,完全预测错误的情况下交叉熵最大,即实际的概率分布和预测的概率分布的最大。
因此交叉熵能很好的作为分类问题的损失函数。

微信支付

支付宝支付