漫游推荐系统(一)—— 概述
本文最后更新于 2024年8月19日 下午
最近在学习推荐系统,Dive
Into Deep
Learning推荐系统篇介绍的非常好,本系列的大部分图也都该章,但是由于其代码实现使用的是mxnet深度学习框架,可能对于一些pytorch用户来说不太友好,此外关于一些细节的解释可能也不尽详细,因此本系列内容将在其基础上,使用pytorch框架实现推荐系统,并对一些细节进行更详细的解释。
需要说明的是,原文中介绍的推荐系统都有一定的年代了,相较于现在工业界的推荐算法,可能有些内容已经过时,但是其基本原理和思想仍然是非常有用的,因此本系列内容将以其为基础,逐步实现一些经典的推荐系统算法。
为什么需要推荐系统
推荐系统本质就是一个信息过滤系统,它可以帮助用户从众多的物品中快速找到自己感兴趣的物品,大大减少用户的时间成本。另一方面,推荐算法通常应用于广告、搜索等领域,可以帮助企业更好地推广自己的产品,具有重要的商业价值。
协同过滤
我们首先引出推荐系统中的一个重要概念,协同过滤(Collaborative Filtering),其通过分析用户或者事物之间的相似性(“协同”),来预测用户可能感兴趣的内容并将此内容推荐给用户。这里的相似性是个很宽泛的概念,可以是用户特征(年龄、性别等)的相似性,也可以是用户行为(比如都喜欢看漫威电影)的相似性。举个例子,用户A和用户B都是22岁的男大学生,并且都在某平台看了很多漫威电影,在这种情况下,协同过滤可能会认为A和B的相似程度很高,于是可能会把A关注但B没有关注的内容推荐给B。
总体而言,协同过滤可以分为两类:基于历史行为的协同过滤和基于模型的协同过滤。
代表性的基于历史行为的CF技术是基于最近邻的CF,可以将其理解为某种聚类算法,它主要有两种实现方式:用户协同过滤和物品协同过滤。用户协同过滤是指给用户推荐和他兴趣相似的用户喜欢的物品,而物品协同过滤是指给用户推荐和他之前喜欢的物品相似的物品。这类模型在处理稀疏或者大规模数据时具有一定局限性,因为它需要计算项目之间的相似性。
像矩阵分解这样的潜在因子模型是基于模型的CF的代表。基于模型的CF在处理稀疏数据时通常比基于历史行为的CF更有效,因为它可以通过学习用户和物品的潜在关系来填补缺失的数据。此外,基于模型的CF具有更高的灵活性和可扩展性,我们可以通过扩展多种神经网络结构来实现不同的推荐算法。
一般来说,CF仅使用用户-项目交互数据来进行推荐和预测。除了这些数据,有些上下文信息可能对推荐系统也是有帮助的,比如用户的历史购买序列。当涉及不同的输入数据时,我们可能需要调整模型的结构,以便更好地捕捉数据之间的关系。
显式反馈和隐式反馈
为了收集用户的偏好,系统会收集用户的反馈信息。在推荐系统中,我们通常会遇到两种类型的反馈:显式反馈(explicit)和隐式反馈(implicit)。显式反馈是指用户明确地表示对物品的喜好,比如用户给电影评分,这种反馈是非常直接的。而隐式反馈则是指用户的行为暗示了他们的喜好,比如用户浏览了某个商品或点击了某个网页,这可能意味着他对这个商品或网页感兴趣。
显然,收集显示反馈需要用户主动参与,而许多用户并不愿意评分或评论,因此显示反馈的获取并不容易。相反,隐式反馈通常可以通过用户的行为数据来获取,比如用户的点击、购买、浏览等行为,这些数据通常是非常丰富的。因此,许多推荐系统都以隐式反馈为中心建模。需要注意,隐式反馈本质上是一种带噪声的数据,我们只能推测用户的喜好和意图。例如用户观看一个视频,我们并不能确定他是否真的喜欢这个视频,因为他可能只是随便点开看看。
推荐任务
在过去的几十年里,人们对许多推荐任务进行了研究。按应用领域,有电影推荐、新闻推荐、商品推荐等。此外还可以根据反馈和输入数据的类型来区分任务。例如,评分预测任务旨在预测用户对物品的显式评分,Top-N推荐任务旨根据隐式反馈推荐给用户最可能感兴趣的物品。如果输入中还包含了序列信息,我们还可以构建序列感知推荐。另一种流行了任务称为点击率预测,它也是基于隐式反馈,但会利用到各种分类特征。
MovieLens数据集
获取数据集
在本系列中,我们将使用一个非常经典的数据集,MovieLens
100k数据集,它包含了用户对电影的评分数据。MovieLens数据集是一个开放的数据集,包含943个用户对1682部电影的10万条评分数据,从1到5分不等。该数据集已经被清洗过以确保每个用户至少评分20部电影。我们可以下载ml-100k.zip并解压u.data文件,该文件包含了用户对电影的评分数据,每一行的格式为user_id、movie_id、rating和timestamp。
我们将在本节实现数据接口,用于加载和处理MovieLens数据集。我们先导入一些包确保后面实验能正确运行,d2l是dive
into deep
learning提供的一个工具包,可以通过pip install d2l安装
1
2
3
4
5
6
7import os
import torch
import pandas as pd
from d2l import torch as d2l
from collections import defaultdict
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset,DataLoaderDataFrame格式加载数据: 1
2
3
4
5
6
7
8
9
10
11
12d2l.DATA_HUB['ml-100k'] = (
'https://files.grouplens.org/datasets/movielens/ml-100k.zip',
'cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')
def read_data_ml100k():
data_dir = d2l.download_extract('ml-100k')
names = ['user_id','item_id','rating','timestamp']
data = pd.read_csv(os.path.join(data_dir,'u.data'),
sep = '\t',names = names,engine='python')
num_users = data['user_id'].unique().shape[0]
num_items = data['item_id'].unique().shape[0]
return data,num_users,num_items
数据集信息
我们先加载数据集并查看前五行的记录: 1
2
3data,num_users,num_items = read_data_ml100k()
print(f'number of users: {num_users}, number of items: {num_items}')
print(data.head(5))1
2
3
4
5
6
7number of users: 943, number of items: 1682
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596user_id、item_id、rating和timestamp。我们可以创建一个\(m \times n\)的评分矩阵\(R\),其中\(m\)是用户数,\(n\)是物品数。如果用户\(u\)对物品\(i\)评分了\(r\),那么\(R_{u,i} = r\),否则\(R_{u,i} =
0\)。矩阵中的值大部分是0,因为用户并没有评分大多数电影。我们可以用稀疏度(sparsity)来衡量矩阵中的非零元素的比例:
\[
\text{sparsity} = \frac{\text{number of zero entries}}{m \times n}
\] 我们可以通过以下代码计算稀疏度: 1
2sparsity = 1 - len(data)/ (num_users * num_items)
print(f'sparsity: {sparsity:f}')1
sparsity: 0.9369531
2
3
4
5d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Rating')
d2l.plt.ylabel('Count')
d2l.plt.title('Distribution of Ratings in MovieLens 100K')
d2l.plt.show()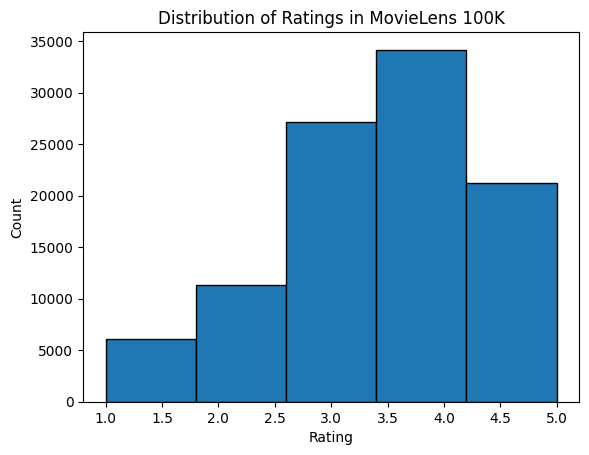
划分数据集
我们将数据集划分为训练集和测试集,下面的split_data_ml100k函数提供random和seq-aware两种划分方式。random模式下不考虑时间戳,100k个交互条目中90%用于训练,10%用于测试,这里我们使用sklearn.model_selection.train_test_split来实现。seq-aware模式下,我们按时间戳对每个用户的交互进行排序,选取用户最后交互的数据作为作为测试,其余作为训练,这种模式将在序列感知的推荐系统章节使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30from sklearn.model_selection import train_test_split
# @save
def split_data_ml100k(data: pd.DataFrame, split_mode='random', test_ratio=0.1):
"""
Split the dataset into training and testing sets.
Parameters:
data (pd.DataFrame): The input dataset.
split_mode (str, optional): The mode for splitting the dataset. Can be 'random' or 'seq-aware'. Defaults to 'random'.
test_ratio (float, optional): The ratio of the dataset to be used for testing. Defaults to 0.1.
Returns:
tuple: A tuple of two pd.DataFrame objects, including the training set and the testing set.
"""
if split_mode == 'seq-aware':
# 按用户和时间戳排序
sorted_data = data.sort_values(['user_id','timestamp'])
# 创建两个dataframe
train_data = pd.DataFrame(columns=data.columns)
test_data = pd.DataFrame(columns=data.columns)
# 按用户分组
for user_id, group in sorted_data.groupby('user_id'):
train_data = pd.concat([train_data, group.iloc[:-1]], ignore_index=True)
# 将时间戳最大的一个样本放入测试集
test_data = pd.concat([test_data, group.iloc[[-1]]], ignore_index=True)
return train_data, test_data
else:
train_data, test_data = train_test_split(data, test_size=test_ratio,
stratify=data['user_id'])
return train_data, test_data
加载数据集
在将数据集划分为训练集和测试集两个DataFrame后,我们需要将其转换为列表和字典/矩阵格式,以便后续的模型训练和评估。下面的load_data_ml100k函数按行读取DataFrame,并存储在users、items和scores列表中。当反馈设置为explicit时,scores记录实际评分,交互inter是一个评分矩阵;当反馈设置为implicit时,scores记录评分为1(表示有交互),交互inter是一个字典,键是用户索引,值是用户交互的物品索引列表,并且物品列表会按时间戳排序(split_data_ml100k中已经排序了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32def load_data_ml100k(data, num_users, num_items, feedback='explicit'):
"""
Load data for the ML-100K dataset.
Args:
data (DataFrame): The input data containing user-item interactions.
num_users (int): The total number of users.
num_items (int): The total number of items.
feedback (str, optional): The type of feedback. Defaults to 'explicit'.
Returns:
tuple: A tuple containing the lists of users, items, scores, and the interaction matrix or dictionary.
"""
# 从0开始编号用户和物品
data['user_id'] = data['user_id'] - 1
data['item_id'] = data['item_id'] - 1
users, items, scores = [], [], []
# 如果是显性反馈,记录评分,否则记录是否有交互
inter = torch.zeros((num_items, num_users)) if feedback == 'explicit' else defaultdict(list)
for line in data.itertuples():
# 生成数据列表
user_id, item_id, score = int(line[1]), int(line[2]), int(line[3])
users.append(user_id)
items.append(item_id)
scores.append(score if feedback == 'explicit' else 1)
# 记录交互信息
if feedback == 'explicit':
inter[item_id, user_id] = score
else:
inter[user_id].append(item_id)
return users, items, scores, intersplit_and_load_ml100k函数将上述函数整合在一起,方便后续实验使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36def split_and_load_ml100k(split_mode='seq_aware', feedback='explicit', test_ratio=0.1, batch_size=256, device='cpu'):
"""
Splits the ML100K dataset into train and test sets, loads the data into tensors, and creates data iterators.
Args:
split_mode (str, optional): The split mode for dividing the dataset. Defaults to 'seq_aware'.
feedback (str, optional): The type of feedback in the dataset. Defaults to 'explicit'.
test_ratio (float, optional): The ratio of the dataset to be used for testing. Defaults to 0.1.
batch_size (int, optional): The batch size for the data iterators. Defaults to 256.
device (str, optional): The device to load the data onto. Defaults to 'cpu'.
Returns:
tuple: A tuple containing the number of users, number of items, training data iterator, and testing data iterator.
"""
# 读取数据
data, num_users, num_items = read_data_ml100k()
# 划分数据集
train_data, test_data = split_data_ml100k(data, split_mode, test_ratio)
# 加载训练数据集
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
# 加载测试数据集
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
# 将数据转换为tensor并包装为dataset
train_set = TensorDataset(torch.tensor(train_u).to(device),
torch.tensor(train_i).to(device),
torch.tensor(train_r, dtype=torch.float).to(device))
test_set = TensorDataset(torch.tensor(test_u).to(device),
torch.tensor(test_i).to(device),
torch.tensor(test_r, dtype=torch.float).to(device))
# 生成数据迭代器
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size)
return num_users, num_items,train_iter,test_iter
我们用下面测试代码查看数据集加载情况: 1
2
3
4
5
6_, _, train_iter, test_iter = split_and_load_ml100k()
for data in train_iter:
users, items, scores = data[0], data[1], data[2]
print(users.shape, items.shape, scores.shape)
print(users[:5], items[:5], scores[:5])
break1
2torch.Size([256]) torch.Size([256]) torch.Size([256])
tensor([108, 511, 378, 721, 733]) tensor([401, 96, 562, 120, 481]) tensor([4., 5., 2., 5., 2.])

微信支付

支付宝支付